Energy-Based Transformers are Scalable Learners and Thinkers
Paper: https://energy-based-transformers.github.io/static/pdfs/paper.pdf1 Website: https://energy-based-transformers.github.io/
TLDR: We outscale (feed-forward) transformers while generalizing reasoning/system 2 thinking to any modality/problem without requiring verifiable rewards😮. Energy-Based Transformers are the first approach to outscale feed-forward transformers across modalities and with respect to several axes including data, depth, parameters, FLOPs, etc. Energy-Based Transformers can think over every single prediction (i.e. every token in language modeling) and generalize better than existing models.
How can we Generalize Reasoning/System 2 Thinking?
Current approaches for reasoning/inference-time compute/System 2 Thinking (I’ll use the term System 2 from now on out just to simplify, the paper contains a strong section on why I believe System 2 is a better term than inference-time compute) in AI generally rely on verifiable rewards, or rewards that cannot be hacked under any circumstance and that can be easily evaluated. An example of a verifiable reward is a solution to a math problem, where we know the answer we want the model to give (i.e., we know the answer to 5 + 5 = 10), and therefore we can check the output of the model being equal to 10.
Seems cool, right? So what are the challenges with this approach?
Well, first off, the approach relies on the problem being easily verifiable (checking the answer is correct easily). Many problems do not take this form, such as creative writing, which is an inherently subjective domain and therefore not easily verifiable. As humans, we can easily think over a wide variety of tasks such as creative writing, relationships, career choices, and coming up with new ideas. Second, existing approaches only really scale well at thoughts performed over text, we want thinking over any modality!2 Lastly, and most importantly, existing approaches rely on human supervision to give rewards. Us humans (and our close animal relatives), were able to learn how to think and reason without any supervision—so a truly intelligent AI should be able to do the same!
So, in an effort to generalize the System 2 capablities of current models, we ask the most important research question of the paper, which is: “Can we rely entirely on unsupervised learning to develop System 2 Thinking?” Relying on unsupervised learning to develop System 2 Thinking would enable models to think on any problem/modality, without relying on any human supervision, just like us humans do!3
So this is the capability we sought after in the paper. But, before we can achieve System 2, we first need to know what capabilities (referred to as Facets of cognition) are necessary for reasoning/System 2. In the paper we identify three capabilities inspired by human cognition, which are:
- The ability to think for longer (dynamic computation allocation)
- The ability to express uncertainty (uncertainty in continuous state spaces)
- The ability to verify whether predictions are correct or not (prediction verification)
While this list may not be completely comprehensive in the quest for human like thinking—these capabilities form the basis for System 2. As an intuitive example, if I asked you a question like: “what’s 57 * 63”, you’d probably first realize that you don’t immediately know the answer (uncertainty and verification), think for a longer amount of time (dynamic computation), and then possibly check (verify) your work! Alternatively, if I asked you “what’s 2 + 2” you’d probably (hopefully :) immediately know the answer is 4, and be able to verify that answer.
We can broadly classify existing paradigms (for now we can focus on the autoregressive case) based on how they predict and whether they have these capabilities.


Ok, now that we know what the necessary prerequisites for System 2, the question becomes, “how can we learn these capabilities from unsupervised learning?” Well, it turns out that there is a very simple and elegant solution that achieves all three of these capabilities at the exact same time. The idea is to first learn a verifier (a model that tells you the goodness/compatibility of a prediction given some context), and then optimize predictions with respect to this verifier. Learning a verifier immediately solves the problems of expressing uncertainty and verifying predictions, and optimizing predictions with respect to this verifier enables dynamic computation through performing optimization for longer.
It turns out that this intuitive idea is actually the definition of Energy-Based Models (EBMs)! EBMs learn to assign a scalar energy value (the verification) denoting the goodness/compatibility/unnormalized probability of a set of variables—which in this case is a context and prediction pair.
The key idea behind EBMs is that configurations with lower energy are more probable and compatible with each other, while configurations with higher energy are less probable. More particularly, the goal of an EBM is to learn an energy function (which maps inputs to a scalar energy; in the case of our paper the energy function is just the entire neural network) that gives lower energy to “correct” or “desirable” configurations, like real data points, and higher energy to “incorrect” or “undesirable” ones, like noise or outliers.
For example, if the given context was a video of a dog running to catch a frisbee, a high energy continuation may be a video of a dog chewing on its toy, while a low energy continuation might be the dog catching the frisee. This dog catching the frisbee scenario is more compatible with the context, which implies lower energy.
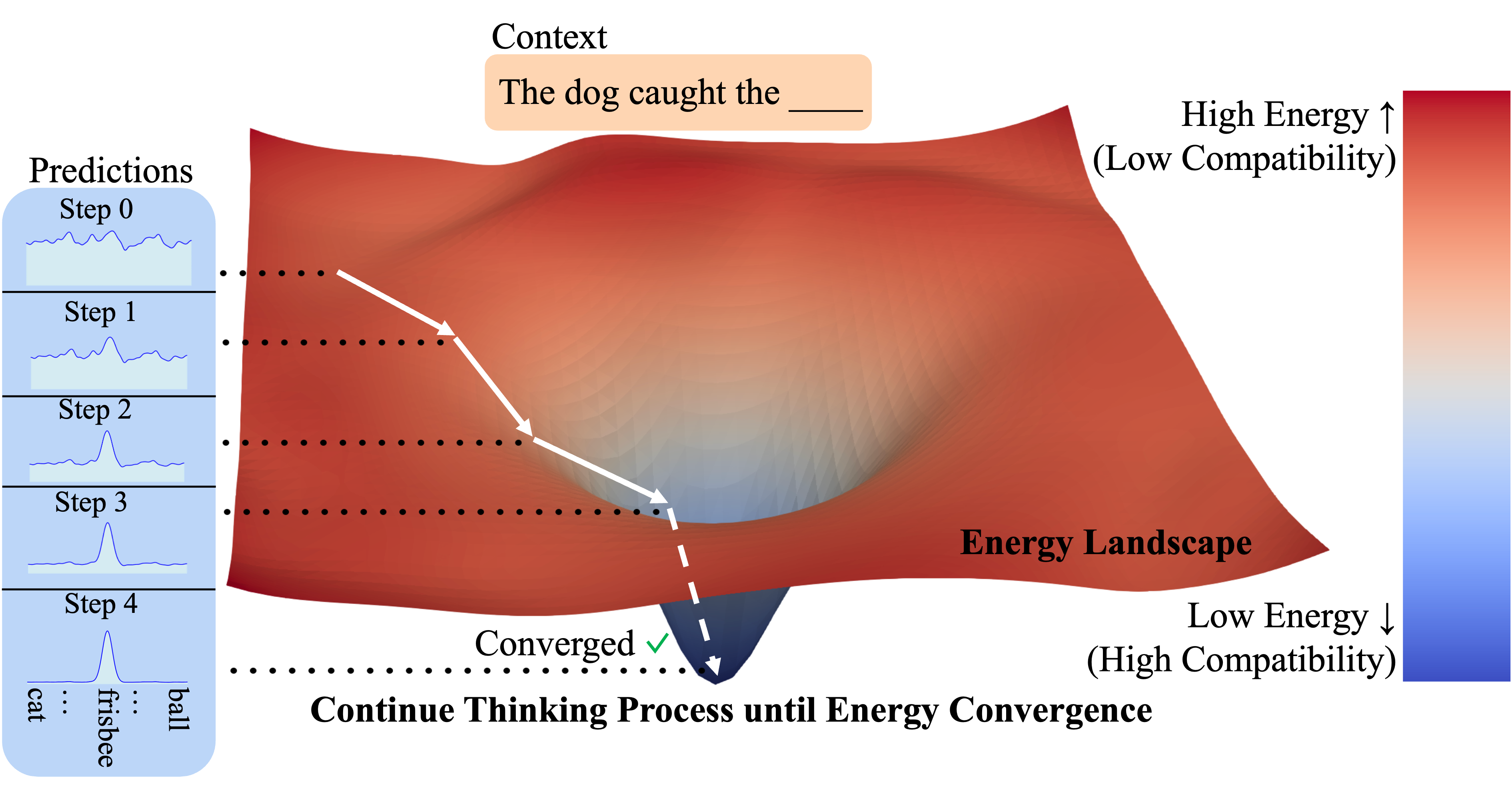
“Thinking” in these EBMs can be performed by starting with an initial (random) prediction, and then optimizing this prediction by minimizing its energy through gradient descent (shown above).
To enable high scalability, we design a specific type of EBMs combined with the Transformer architecture and with a scalable training algorithm, which we call Energy-Based Transformers (EBTs); EBTs enable high training efficiency, stability, and parallelizability. We discover several tricks for training EBTs at scale as well as for enabling System 2 to emerge during pretraining. For more information and details on how these EBTs are actually trained, please reference the approach section of the paper.
Ok, so hopefully by now the intuition of EBTs make sense—but how do they actually work in practice, does the thinking actually help performance? We conducted experiments to test this by comparing EBTs against standard feed-forward Transformers (we use the SOTA recipe from the Mamba paper called the Transformer++) on tasks such as language modeling. You can see from the left subfigure that thinking with EBTs significantly improves performance over feed-forward Transformers. Particularly, by thinking for longer and also self-verifying EBTs can out-generalize feed-forward transformers to Out-of Distribution (OOD) data. It’s important to note that EBTs here are improving the performance of every single next token, and not just a final reasoning accuracy like current “reasoning” foundation models. The right subfigure also demonstrates promising results, where the performance from thinking improves with scale, suggesting that EBTs trained at scale will benefit even more from thinking than EBTs trained at the current smaller scale.
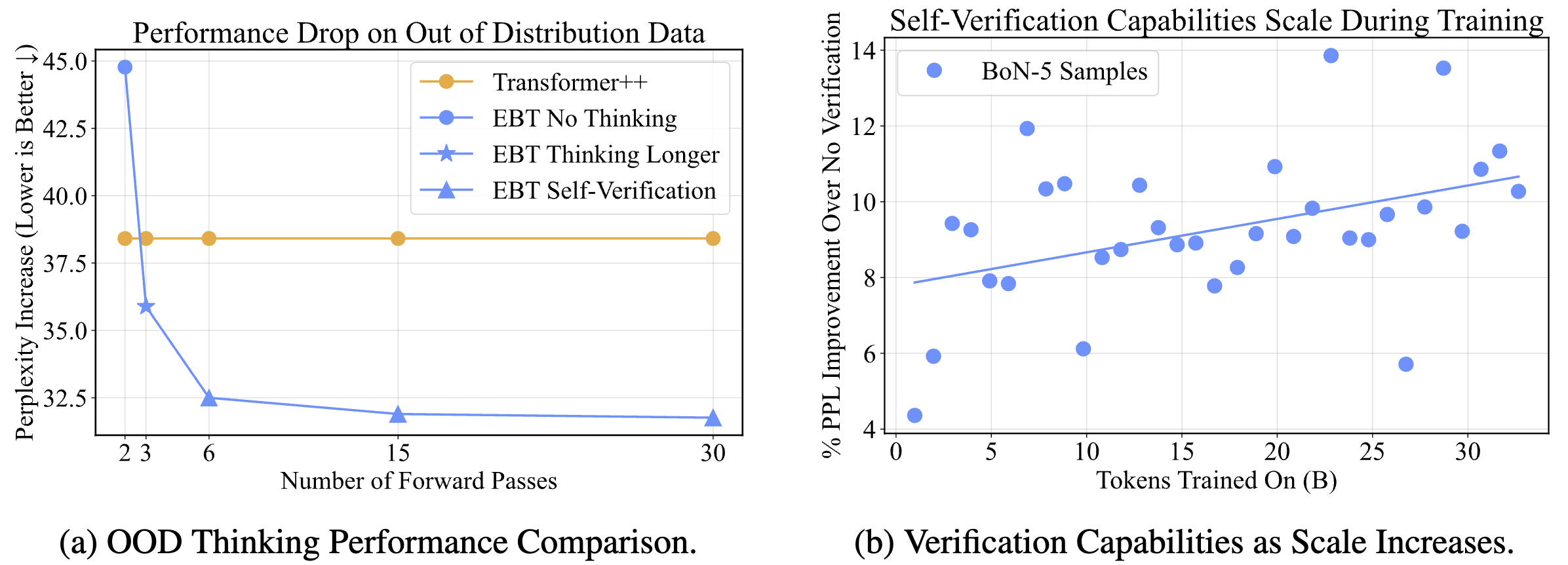
Another amazing result (that needs to be tested more) is the effect of System 2 Thinking on generalization to data that varies in Out-of-Distribution (OOD) magnitude (how far away data is from the training distribution). For example, below we can see a plot demonstrating that as data becomes more OOD, the performance gains from thinking increase. This aligns with results in psychology, where System 2 in humans is used to generalize to new unseen scenarios.

Ok so we have Generalized System 2 Thinking, but…
How Come this Outscales (Feed-Forward) Transformers?
This is a good question that does not have as definitive of an answer as generalizing reasoning, however, I can give a general intuition backed by two main reasons for why I believe this is occurring:
- Learning to verify is (generally) easier than learning to generate.4 EBTs learn to verify (so that they can generate), whereas feed-forward models just learn to directly generate. Therefore, EBTs generalize better, and this improved generalization leads to improved scaling.
- EBTs make weaker assumptions about the data prediction process than feed-forward Transformers, while enabling higher model flexibility (predicting data by optimizing w.r.t a verifier, which can involve many forward passes, vs. feed-forward transformers which need to predict data within a single forward pass). Generally, in AI, systems that increase flexibility and decrease assumptions win out over time (there is a great talk by Hyung Won Chung on this). Thus, it makes sense under this perspective that EBTs scale better.
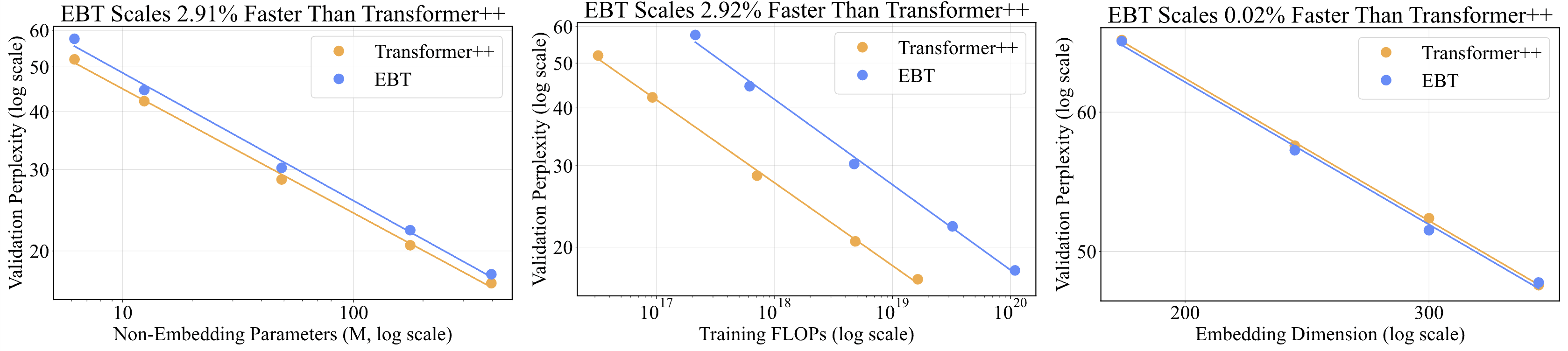
We conducted several scaling experiments to be as thorough as possible in determining how EBTs scale compared to feed-forward transformers. For example, in all of the experiments shown below for language modeling, we determine the scaling rate of EBTs compared to the Transformer++ by changing just a single independent variable (as is commonly done in science, but not in empirical “scaling law” papers5).
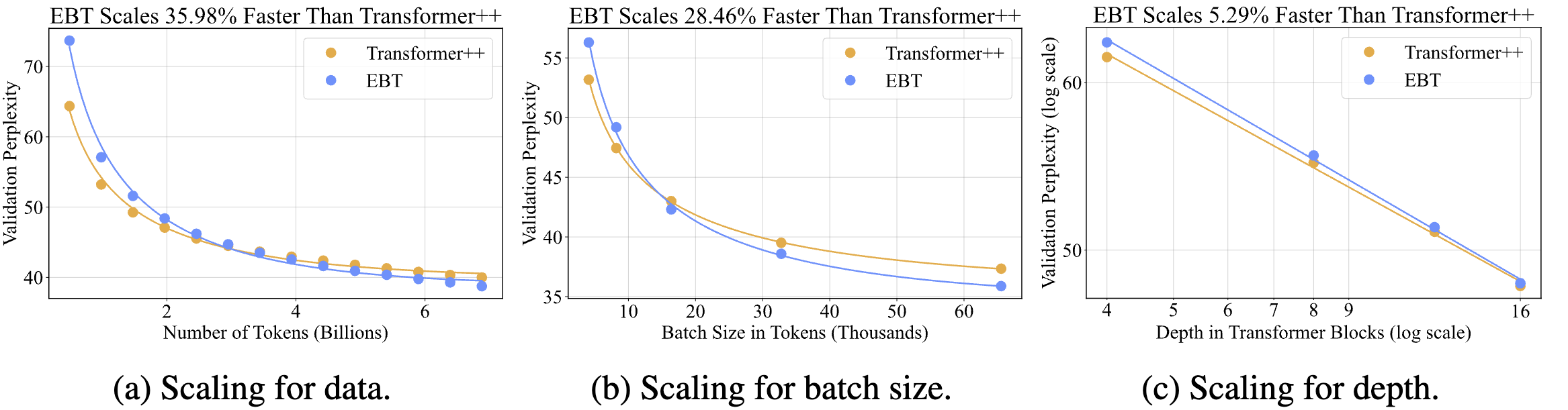
Remarkably, the plots demonstrate that EBTs scale up to 35% faster than feed-forward Transformers for data!! This is perhaps the most impressive result of the paper as it suggests that EBTs are 35% more data-efficient than Transformers. This essentially means that at scale, if you needed 30T tokens for a feed-forward Transformer, you’d need less than 20T for an EBT to achieve the same pretraining perplexity. Almost as impressive is that on downstream tasks, with the same pretraining perplexity, EBTs outperform the Transformer++, suggesting better generalization (these results are in the paper). Together, these results suggest that you can get significantly better downstream task performance while using less data with EBTs compared to the standard Transformer++. The results in the other two plots also demonstrate a similar out-scaling trend for EBTs compared to the Transformer++ when it comes to batch size as well as depth.
In fact, if we zoom in a little bit into a similar plot from a scaled up experiment we see that the gap in performance between EBTs and the Transformer++ is actually increasing over time! (Note that this line was fit with a log function).

We see similar (although less dramatic) outscaling of EBTs compared to the Transformer++ for parameter/FLOP efficiency (at the scale we tested at, EBTs still lag behind in raw y axis performance, but scale at a higher rate, and therefore would perform better than the Transformer++ asymptotically if these trends continue).
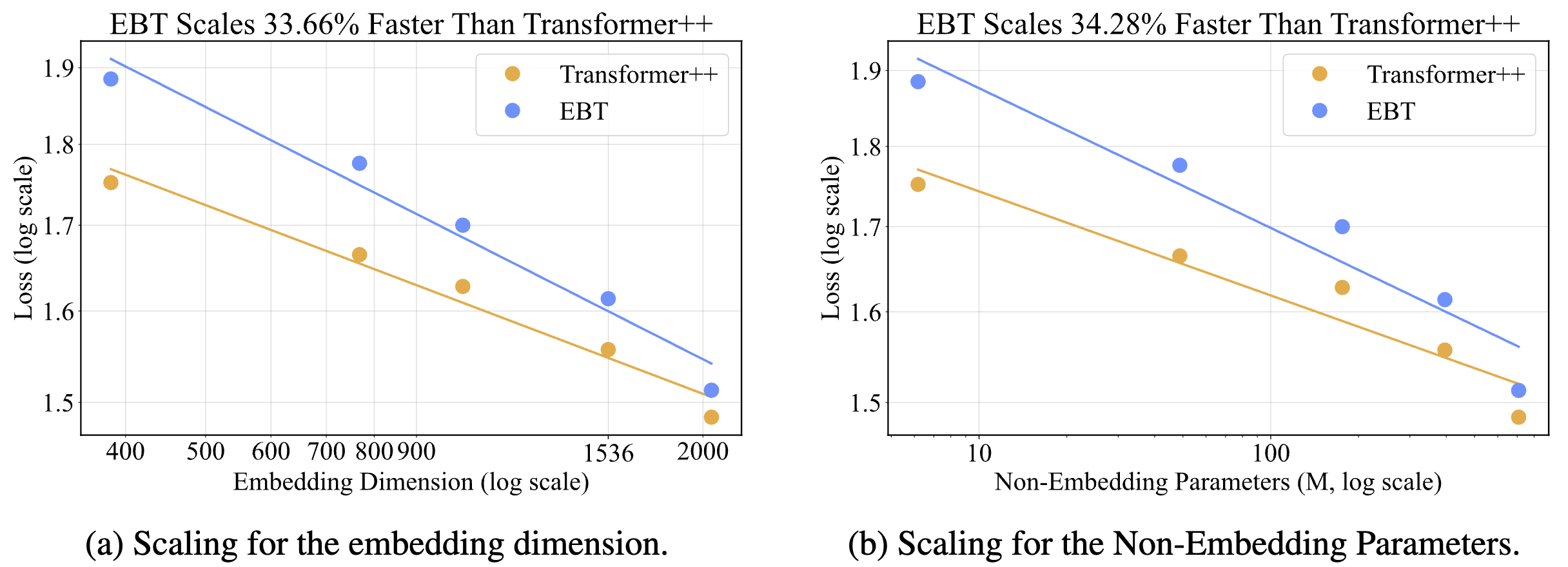
In CV, we observe that EBTs very dramatically outscale the Transformer++ at predicting the next frame, achieving a 33% and 34% higher scaling rate for width (embedding dimension) and parameters respectively. (These trends are less consistent than the scaling trends in language modeling though.)
We also compared EBTs to DiTs in simple image denoising tasks and achieved very promising results (better quality with less forward passes). For more information on how EBTs work and any details including pseudocode please feel free to reference the paper!
Conclusion and a Sprinkle of Intuition
While the results are promising, there is a long way to go in scaling these models up (I’m mainly looking at you, potential stability issues). But, I’m confident that in the next 3 years EBTs (or some variant) will be pretty common (let’s check back and see:). The main reason I see EBTs being adopted, at least in the short term, is the improved generalization and data efficiency (in fact, these things go hand in hand as better generalization -> better data learning efficiency). Strong generalization is by far the most important aspect of any given model (as what else really matters besides generalization), and data efficiency has become increasingly important (see this video by the OpenAI pre-training team where they mention that the biggest blocker to AI progress is more data-efficient algorithms)! For these reasons alone I’m confident there will be high interest in EBTs, in addition to the System 2 capabilities, but we shall see as the world is challenging to predict.
Generally, approaches that increase the flexibility of models scale best in the long run (i.e., see CNNs -> ViTs, statistical learning -> NNs, almost all of AI as a field in general). EBTs are just the next example of this, where (if we squint a little bit) EBTs are more flexible than DiTs6, which are more flexible than standard feed-forward models such as RNNs and traditional transformers (assuming they only update with new state information, more on this nuance in the paper).
Thanks to all coauthors for all the help with this work, and I’m super excited to see what this work leads to in the future! Feel free to check the paper for more information and details/references.
Footnotes
-
The old version of this paper was called “Cognitively-Inspired Energy Based World Models or EBWM” but because of me starting my PhD, working with other people, along with some other things, we thought a rebrand was fitting. We also conducted much more thorough experiments due to having additional compute. ↩
-
While there are approaches for multimodal reasoning, these generally still have models think by outputting text. Thinking over continuous signals using RL at scale has not yet succeeded to my knowledge. ↩
-
The paper discusses other forms of System 2 in more depth, such as diffusion/RNNs. ↩
-
The intuition section of the paper does a good job at explaining why this is the case, making connections to theoretical computer science. But, just for flavor, consider the case of a maze. What’s more likely to generalize—the maze generator (which has to generate a solution in a single forward pass) or the maze verifier (which only has to verify the correctness of a solution in a single forward pass)? ↩
-
We also do “scaling law” runs where we vary several independent variables at once following common practice in other ML papers. However, I’d argue these experiments are much less informative than experiments where just a single independent variable is changed at a time, as these scaling law experiments generally involve changing several parameters at once (data, batch size, depth, width, etc) meaning it’s not possible to isolate which axes two different models scale better/worse compared to one another. Changing a single indenpendent variable (one axis) at a time allows us to directly measure these things—this follows standard scientific methodology :). ↩
-
We reference the reader to the paper section comparing diffusion and EBMs in depth for why EBMs are more flexible. The TLDR is EBMs are a generalization of diffusion and allow for estimating (unnormalized) likelihoods or verifying at every step of the thinking process, whereas diffusion models only do this implicitly after the entire denoising process. ↩
Enjoy Reading This Article?
Here are some more articles you might like to read next: