Training for Marathons by Sprinting---Why Exposure Bias is Evil
Let me tell you about a friend of mine. He’s a big runner—he loves marathons and he’s actually pretty good at them.
But he’s pretty dumb.
He practices for marathons by sprinting 100M dashes, even though this is 0.237% (1/422nd) of a marathon…
Somehow this works for him, but it’s very clearly suboptimal.
You’d think he would practice for marathons by running a couple miles, or even a half marathon. But nope, 1/422nd of the marathon.
I keep telling him to practice for longer distances, but he won’t listen…
Actually, you may know this friend, he’s pretty famous.
His name is Autoregression… and it turns out his best friend Diffusion does the same thing.
Sound crazy…? Let me take a step back.
When we train autoregressive models, we train them to predict a single step—given some real context, predict the next token/patch. Diffusion models are the exact same story—take a real image/sequence, add some noise, and train the model to undo just that single step of noise.

But at inference time, these models are used completely differently… Autoregressive models generate thousands of tokens sequentially, feeding every prediction back in as context for the next one. Diffusion models start from pure noise and denoise step by step, where each step builds on the last. In other words, at inference these models run like RNNs—their own (possibly wrong) outputs become their next inputs.
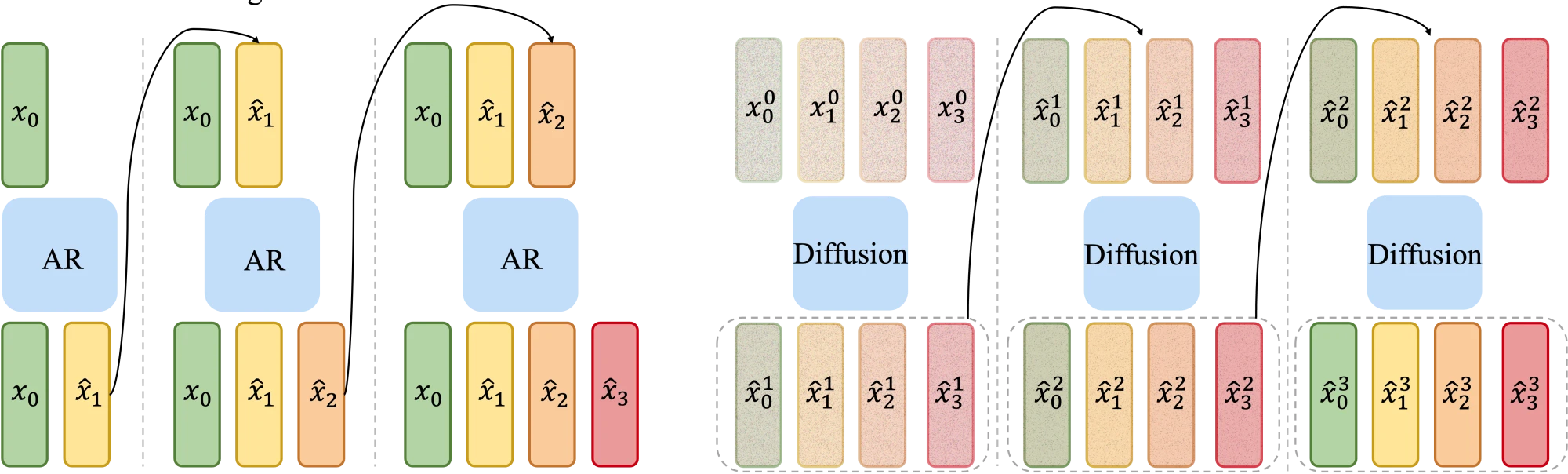
The analogy here is we train the models to run 100M dashes (a single prediction step), and then inference them on marathons (thousands or even more steps).
This sucks in pretty much every way, shape, and form. During training, models only ever see ground-truth data, but at inference, they see their own predictions, which are never perfect. This results in inputs that slowly drift away from anything the model saw during training (a distribution shift), and because every step feeds the next, small errors compound into larger ones. The longer a model generates, the worse things get—you’ve probably seen this firsthand with video generation models that melt into mush after ten seconds, or LLMs that get less coherent over really long generations.
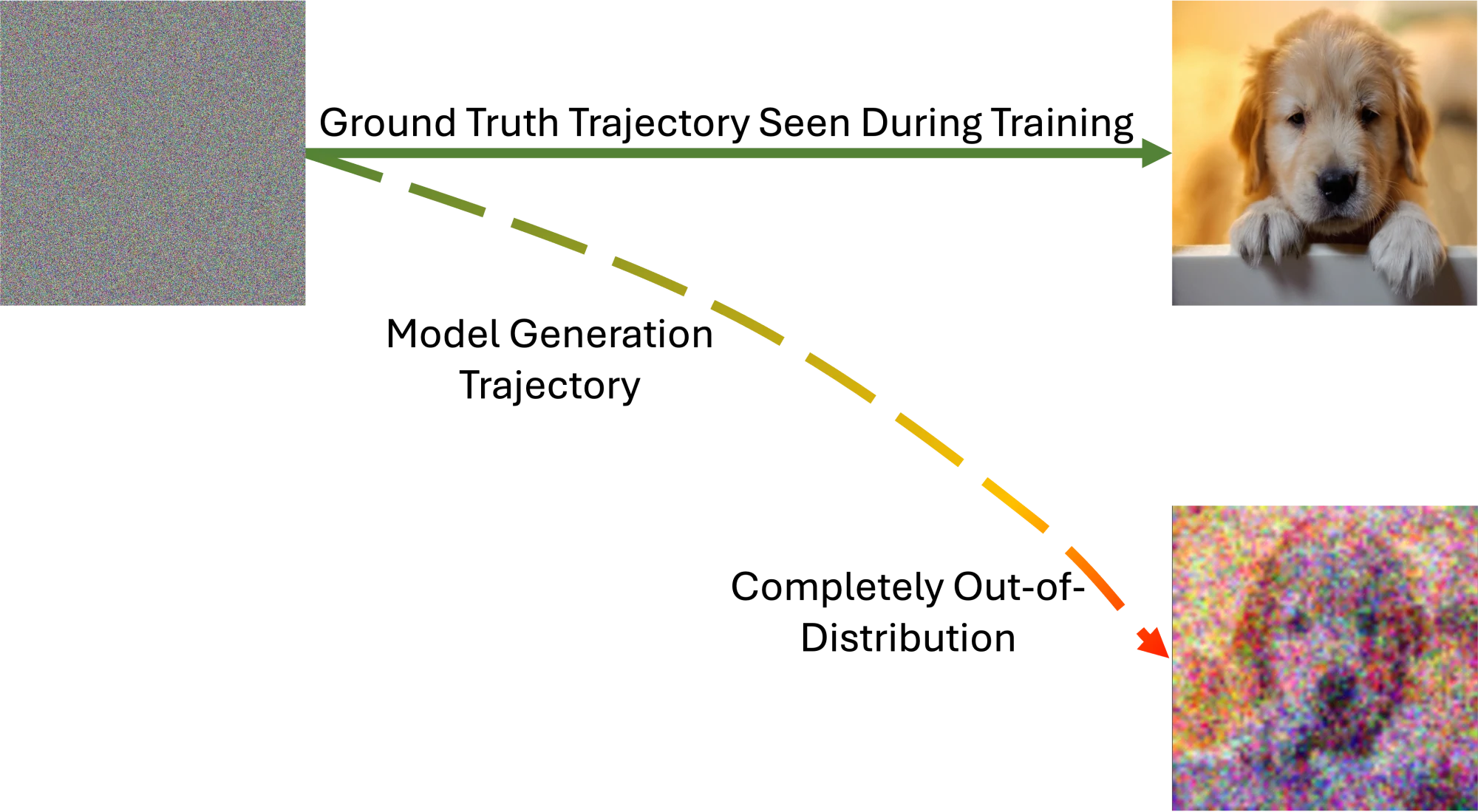
We know neural networks don’t generalize out-of-distribution very well. Yet, the BIG TWO generative models we use every day go out-of-distribution by design; they are trained on a single step and inferenced on thousands or even millions of steps.
Your gut instinct here should be: wtf?!?! How do these models even work?
It turns out this is a well-known problem, broadly referred to as exposure bias: models are only ever trained on ground-truth data (this is broadly called teacher forcing), but then suffer from exposure at inference to their own mistakes.
People have been trying to solve the exposure bias problem for a while now… and unfortunately, nothing very elegant has come of it. Lots of solutions can reduce the exposure bias issue for a couple of steps (i.e., like the rollout loss with VJepa2, or self-forcing/diffusion forcing for diffusion models), but nothing can reduce exposure bias indefinitely in a pre-training aligned manner.
Readers familiar with consistency models or MeanFlow models may be tempted to believe these single-step models fix the exposure bias issue, since they can perform inference in a single step. But they actually suffer from the same problem in a different form—their training mostly consists of small jumps along the trajectory, while inference asks for one giant jump. This still leads to a large mismatch between training and inference.
It turns out there’s a fundamental reason that modern generative models are trained this way, and getting rid of this nastiness is not easy.
Our paper on Explorative Modeling will demonstrate a new way of generative modeling that enables solving this, so more on the challenge of exposure bias is coming very soon :)
Enjoy Reading This Article?
Here are some more articles you might like to read next: